FAQs
You can’t find what you’re looking for? Below you’ll find answers to a few of our frequently asked questions.
How can I run a scan?
Once you’ve completed the ScanCode.io app installation, you simply start by creating a new project and run the appropriate pipeline.
ScanCode.io offers several Built-in Pipelines depending on your input, see the Which pipeline should I use? below.
As an alternative, If you simply wish to run a pipeline without installing ScanCode.io you may use the Docker image to run pipelines as a single command:
docker run --rm \
-v "$(pwd)":/codedrop \
ghcr.io/aboutcode-org/scancode.io:latest \
run scan_codebase /codedrop \
> results.json
Refer to the $ run PIPELINE_NAME [PIPELINE_NAME …] input_location section for more about this approach.
Tip
Prefer a one-liner? Use this to scan your current directory:
curl -sSL https://raw.githubusercontent.com/aboutcode-org/scancode.io/main/etc/scripts/run-scan.sh | bash
Which pipeline should I use?
Selecting the right pipeline for your needs depends primarily on the type of input data you have available. Here are some general guidelines based on different input scenarios:
If you have a Docker image as input, use the analyze_docker_image pipeline.
For a full codebase compressed as an archive, optionally also with it’s pre-resolved dependencies, and want to detect all the packages present linked with their respective files, use the scan_codebase pipeline.
If you have a single package archive, and you want to get information on licenses, copyrights and package metadata for it, opt for the scan_single_package pipeline.
When dealing with a Linux root filesystem (rootfs), the analyze_root_filesystem_or_vm_image pipeline is the appropriate choice.
For processing the results of a ScanCode-toolkit scan or ScanCode.io scan, use the load_inventory pipeline.
When you want to import SPDX/CycloneDX SBOMs or ABOUT files into a project, use the load_sbom pipeline.
When you have lockfiles or other package manifests in a codebase and you want to resolve packages from their package requirements, use the resolve_dependencies pipeline.
When you have application package archives/codebases and optionally also their pre-resolved dependencies and you want to inspect packages present in the package manifests and dependency, use the inspect_packages pipeline.
For scenarios involving both a development and deployment codebase, consider using the map_deploy_to_develop pipeline.
For getting the DWARF debug symbol compilation unit paths when available from an elf binary. use the inspect_elf_binaries pipeline.
These pipelines will automatically execute the necessary steps to scan and create the packages, dependencies, and resources for your project based on the input data provided.
After executing one of the pipelines mentioned above, you have the option to augment your project’s data by executing additional pipelines, often referred to as addon pipelines. These additional pipelines offer further enhancements and modifications to your existing data, allowing for more comprehensive analysis and insights.
If you wish to find vulnerabilities for packages and dependencies, you can use the find_vulnerabilities pipeline. Note that setting up VulnerableCode is required for this pipeline to function properly.
To populate PurlDB with the packages discovered in your project, use the populate_purldb pipeline. Before executing this pipeline, make sure to set up PurlDB.
To match your project codebase resources to MatchCode.io for Package matches, utilize the match_to_matchcode pipeline. It’s essential to set up MatchCode.io before executing this pipeline.
What input types are supported?
ScanCode.io supports multiple input types for your projects:
File Upload: Upload archives, source files, packages, or SBOMs directly. See File Upload.
Download URL: Provide an HTTP/HTTPS URL to fetch remote files. See Download URL.
Package URL (PURL): Reference packages from popular registries (npm, PyPI, Maven, Cargo, NuGet, RubyGems, and more) using the PURL specification. See Package URL (PURL).
Docker Reference: Fetch Docker images directly from container registries using the
docker://syntax. See Docker Reference.Git Repository: Clone a Git repository using its HTTPS URL. See Git Repository.
JFrog Artifactory: Fetch artifacts from on-premise or cloud Artifactory repositories. See JFrog Artifactory.
Sonatype Nexus: Fetch artifacts from Nexus Repository Manager instances. See Sonatype Nexus.
For complete details on all input methods, refer to the Inputs documentation.
What is the difference between scan_codebase and scan_single_package pipelines?
The key differences are that the scan_single_package pipeline treats the input as if it were a single package, such as a package archive, and computes a License clarity and a Scan summary to aggregate the package scan data:
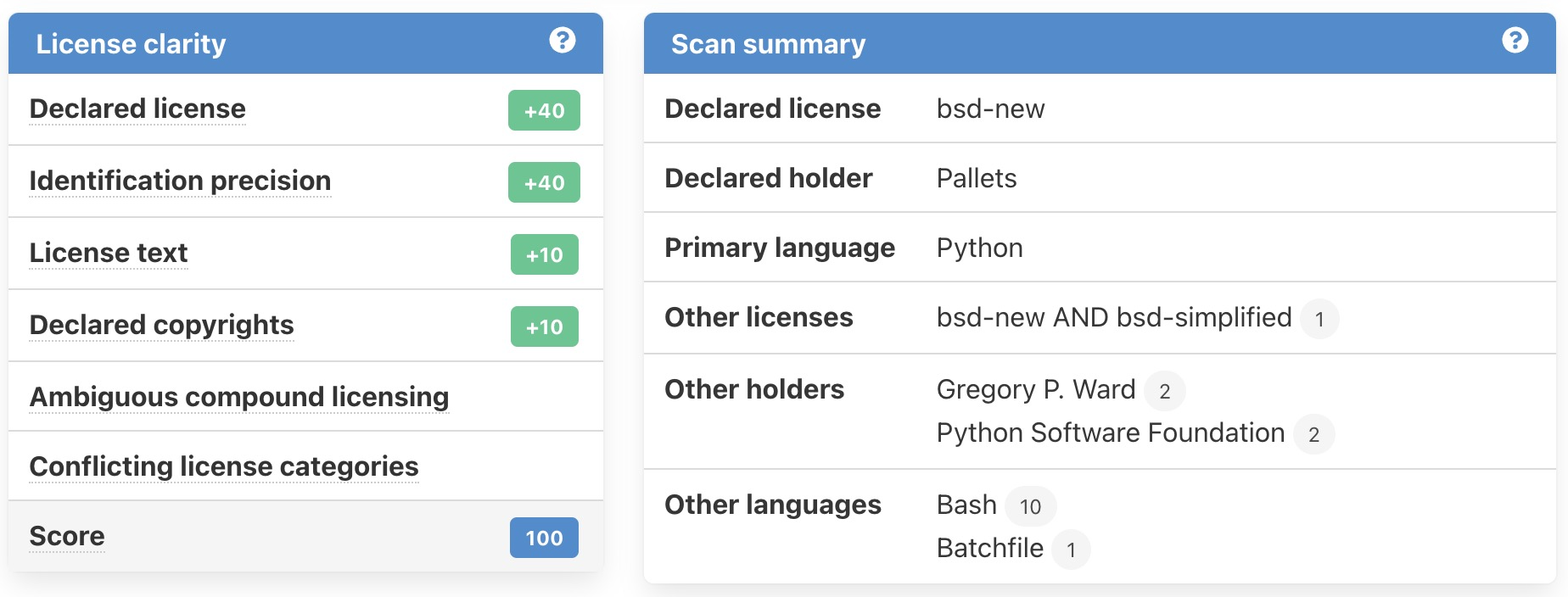
In contrast, the scan_codebase pipeline is more of a general purpose pipeline and makes no such single package assumption. It does not compute such summary.
You can also have a look at the different steps for each pipeline from the Built-in Pipelines documentation.
How to create multiple projects at once?
You can use the $ scanpipe batch-create [–input-directory INPUT_DIRECTORY] [–input-list FILENAME.csv] command to create multiple projects simultaneously. This command processes all files in a specified input directory, creating one project per file. Each project is uniquely named using the file name and a timestamp by default.
For example, to create multiple projects from files in a directory named
local-data/:
$ docker compose run --rm \
--volume local-data/:/input-data:ro \
web scanpipe batch-create /input-data
Options:
Custom Pipelines: Use the
--pipelineoption to add specific pipelines to the projects.Asynchronous Execution: Add
--executeand--asyncto queue pipeline execution for worker processing.Project Notes and Labels: Use
--notesand--labelto include metadata.
Each file in the input directory will result in the creation of a corresponding project, ready for pipeline execution.
Can I run multiple pipelines in parallel?
Yes, you can run multiple pipelines in parallel by starting your Docker containers with the desired number of workers using the following command:
docker compose up --scale worker=2
Note
You can also add extra workers by running the command while the ScanCode.io services are already running. For example, to add 2 extra workers to the 2 currently running ones, use the following command:
sudo docker compose up --scale worker=4
Can I pause/resume a running pipeline?
You can stop/terminate a running pipeline but it will not be possible to resume it. Although, as a workaround if you run ScanCode.io on desktop or laptop, you can pause/unpause the running Docker containers with:
docker compose pause # to pause/suspend
docker compose unpause # to unpause/resume
What tool does ScanCode.io use to analyze docker images?
The following tools and libraries are used during the docker images analysis pipeline:
container-inspector and debian-inspector for handling containers and distros.
fetchcode-container to download containers and images.
scancode-toolkit for application package scans and system package scans.
extractcode for universal and reliable archive extraction.
Specific handling of windows containers is done in scancode-toolkit to process the windows registry.
Secondary libraries and plugins from scancode-plugins.
The pipeline documentation is available at Analyze Docker Image and its source code at docker.py. It is hopefully designed to be simple and readable code.
Am I able to run ScanCode.io on Windows?
Yes, you can use the Run with Docker installation. However, please be sure to carefully read the warnings, as running on Windows may have certain limitations or challenges.
Is it possible to compare scan results?
At the moment, you can only download full reports in JSON and XLSX formats. Please refer to our Output Files section for more details on the output formats.
How can I trigger a pipeline scan from a CI/CD, such as Jenkins, TeamCity or Azure Devops?
You can refer to the Automation to automate your projects management.
Also, A new GitHub action is available at scancode-action repository to run ScanCode.io pipelines from your GitHub Workflows.
How can I get notified about my project progression?
You can monitor your project’s progress in multiple ways:
User Interface: The project details page provides real-time updates on pipeline execution.
REST API: Use the API to programmatically check the status of your projects.
CLI Monitoring: The
scanpipe list-projectscommand provides an overview of project states.Webhook Integration: You can set up webhooks to receive updates in your preferred notification system. For more details, refer to the Webhooks section.
Slack notifications: Get project updates directly in Slack by configuring an incoming webhook. See Slack Notifications for setup instructions.
How to tag input files?
Certain pipelines, including the Map Deploy To Develop, require input files to be tagged. This section outlines various methods to tag input files based on your project management context.
Using download URLs as inputs
You can provide tags using the “#<fragment>” section of URLs. This tagging method is universally applicable in the User Interface, REST API, and Command Line Interface.
Example:
https://url.com/sources.zip#from
https://url.com/binaries.zip#to
Uploading local files
There are multiple ways to tag input files when uploading local files:
User Interface: Utilize the “Edit flag” link in the “Inputs” panel of the Project details view.
REST API: Use the “upload_file_tag” field in addition to the “upload_file” field.
Command Line Interface: Tag uploaded files using the “filename:tag” syntax. Example:
--input-file path/filename:tag.
How to fetch files from private sources and protected by credentials?
Several Fetch Authentication settings are available to define the credentials required to access your private files, depending on the authentication type:
Example for GitHub private repository files:
SCANCODEIO_FETCH_HEADERS="github.com=Authorization=token <YOUR_TOKEN>"
Example for Docker private repository:
SCANCODEIO_SKOPEO_CREDENTIALS="registry.com=user:password"
Can I use a git repository as project input?
Yes, as an alternative to an uploaded file, or an download URL targeting an archive, you may directly provide the URL to a git repository. The repository will be cloned in the project inputs, fetching only the latest commit history, at the start of a pipeline execution.
Note that only the HTTPS type of URL is supported:
https://<host>[:<port>]/<path-to-git-repo>.git`
A GitHub repository URL example:
https://github.com/username/repository.git
How can I provide my license policies?
For detailed information about the policies system, refer to License Policies and Compliance Alerts.
Can you analyze Dockerfiles?
We have code in https://github.com/aboutcode-org/container-inspector/blob/main/src/container_inspector/dockerfile.py for this … but this may not be wired in other tools at the moment. It can for instance map dockerfile instructions to actual docker image history, https://github.com/aboutcode-org/container-inspector/blob/main/src/container_inspector/dockerfile.py#L204
Can you analyze a built image? (Build Docker Image Analysis)
Yes, we do this in ScanCode.io. We have one fairly unique feature to actually account for all files used in all layers.
Can you analyze all layers of a running container?
ScanCode.io scans all layers of images. We can scan all layers of a running container if you save the running container as an image first. We can also fetch images from registries, local files and technically also from a running container, say in a local docker … but this has not yet been tested so far. We do not introspect k8s clusters to analyze the deployed and running images there (yet) and that would be a nice future addition. For now we can instead work on the many images there, save and analyze them.
Can you analyze Docker in Docker?
The input to ScanCode is a local saved image: Docker or OCI. Docker in Docker support will demand to have access to the saved images (either extracted from the Docker images in Docker, or mounted in a volume or saved from the Docker in the Docker image). Once saved we can analyze these alright.
Can I import SBOM from other SCA tools?
Yes! You can load SBOMs generated by other tools for further review and run pipelines to enrich or validate the data directly in ScanCode.io.
While most valid SBOMs should work out of the box, SBOMs from the following tools are actively supported and tested:
- Anchore: https://anchore.com/sbom/
- CycloneDX cdxgen: https://cyclonedx.github.io/cdxgen/
- OWASP dep-scan: https://owasp.org/www-project-dep-scan/
- OSS Review Toolkit (ORT): https://oss-review-toolkit.org/ort/
- OSV-Scanner: https://osv.dev/
- SBOM tool: https://github.com/microsoft/sbom-tool/
- Trivy: https://trivy.dev/
Note
Imported SBOMs must follow the SPDX or CycloneDX standards, in JSON format.
You can use the load_sbom pipeline to process and enhance these SBOMs in your
ScanCode.io projects.